
The results were null, indicating that there may not be much to this effect.
The first author of the original study, Fritz Strack, was invited to comment. In his comment, Strack makes four criticisms of the original study that, in his view, undermine the results of the RRR to some degree. I am not convinced by these arguments; below, I address each in sequence.
"Hypothesis-aware subjects eliminate the effect."
First, Strack says that participants may have learned of the effect in class and thus failed to demonstrate it. To support this argument, he performs a post-hoc analysis demonstrating that the 14 studies using psychology pools found an effect size of d = -0.03, whereas the three studies using non-psychology undergrad pools found an effect size of d = 0.16, p = .037.However, the RRR took pains to exclude hypothesis-aware subjects. Psychology students were also, we are told, recruited prior to coverage of the Strack et al. study in their classes. Neither of these steps ensure that all hypothesis-aware subjects were removed, of course, but it certainly helps. And as Sanjay Srivastava points out, why would hypothesis awareness necessarily shrink the effect? It could just as well enhance it by demand characteristics.
Also, d = 0.16 is quite small -- like, 480-per-group for a one-tailed 80% power test small. If Strack is correct, and the true effect size is indeed d = 0.16, this would seem to be a very thin success for the Facial Feedback Hypothesis, and still far from consistent with the original study's effect.
"The Far Side isn't funny anymore."
Second, Strack suggests that, despite the stimulus testing data indicating otherwise, perhaps The Far Side is too 1980s to provide an effective stimulus.I am not sure why he feels it necessary to disregard the data, which indicates that these cartoons sit nicely in the midpoint of the scale. I am also at a loss as to why the cartoons need to be unambiguously funny -- had the cartoons been too funny, one could have argued there was a ceiling effect.
"Cameras obliterate the facial feedback effect."
Third, Strack suggests that the "RRR labs deviated from the original study by directing a camera at the participants." He argues that research on objective self-awareness demonstrates that cameras induce subjective self-focus, tampering with the emotional response.This argument would be more compelling if any studies were cited, but in either case, I feel the burden of proof rests with this novel hypothesis that the facial feedback effect is moderated by the presence of cameras.
"The RRR shows signs of small-study effects."
Finally, Strack closes by using a funnel plot to suggest that the RRR results are suffering from a statistical anomaly.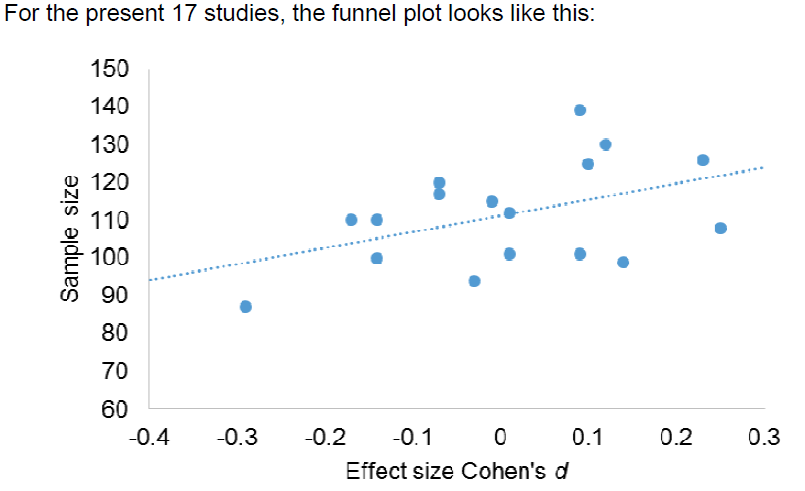
He shows a funnel plot that compares sample size and Cohen's d, arguing that it is not appropriately pyramidal. (Indeed, it looks rather frisbee-shaped.)
Further, he conducts a correlation test between sample size and Cohen's d. This result is not, strictly speaking, statistically significant (p = .069), but he interprets it all the same as a warning sign. (It bears mention here that an Egger test with an additive error term is a more appropriate test. Such a test yields p = .235, quite far from significance.)
Strack says that he does not mean to insinuate that there is "reverse p-hacking" at play, but I am not sure how else we are to interpret this criticism. In any case, he recommends that "the current anomaly needs to be further explored," which I will below.

Strack's funnel plot does not appear pyramidal because the studies are all of roughly equal size, and so the default scale of the axes is way off. Here I present a funnel plot with axes of more appropriate scale. Again, the datapoints do not form a pyramid shape, but we see now that this is because there is little variance in sample size or standard error with which to make a pyramid shape. You're used to seeing taller, more funnel-y funnels because sample sizes in social psych tend to range broadly from 40 to 400, whereas here they vary narrowly from 80 to 140.
You can also see that there's really only one of the 17 studies that contributes to the correlation, having a negative effect size and larger standard error. This study is still well within the range of all the other results, of course; together, the studies are very nicely homogeneous (I^2 = 0%, tau^2 = 0), indicating that there's no evidence this study's results measure a different true effect size.
Still, this study has influence on the funnel plot -- it has a Cook's distance of 0.46, whereas all the others have distances of 0.20 or less. Removing this one study abolishes the correlation between d and sample size (r(14) = .27, p = .304), and the resulting meta-analysis is still quite null (raw effect size = 0.04, [-0.09, 0.18]). Strack is interpreting a correlation that hinges upon one influential observation.
I am willing to bet that this purported small-study effect is a pattern detected in noise. (Not that it was ever statistically significant in the first place.)
Admittedly, I am sensitive to the suggestion that an RRR would somehow be marred by reverse p-hacking. If all the safeguards of an RRR can't stop psychologists from reaching whatever their predetermined result, we are completely and utterly fucked, and it's time to pursue a more productive career in refrigerator maintenance.
Fortunately, that does not seem to be the case. The RRR does not show evidence of small-study effects or reverse p-hacking, and its null result is robust to exclusion of the most negative result.
To the comment that hypothesis aware subjects attenuate effect sizes: yes (usually)
ReplyDeletehttp://pss.sagepub.com/content/26/7/1131.short
I've read the article, but I can't find anything about hypothesis aware subjects behaving differently. The paper seems to show data about people who take part in the same study twice, but I can't find anything about whether they 1) were aware of any hypothesis and/or 2) whether this influenced responses.
DeleteFrom the discussion:
"Effect sizes observed at Wave 2 were generally smaller
than those observed at Wave 1, but this difference was
not uniformly statistically significant. Larger effect sizes were more likely to demonstrate a significant reduction, perhaps because observable between-conditions variance is constrained for true effects that are closer to zero. Additionally, some effects may be more susceptible than others to attenuation"
&
"While there is no direct evidence of a mechanism underlying this decline, one possible explanation is that asking questions multiple times may lead to elaboration (Sherman,1980; Sturgis et al., 2009)"
I see no evidence for the statement that hypothesis aware subjects attenuate effect sizes. Am I missing something?
Aside from that, (presumably) people in the RRR did not take part in this study for the 2nd time and, as been explained in the above post, the RRR took pains to exclude hypothesis-aware subjects.